Mem0 thinks our 2023 conversation happened in 2026
We've been building Aurra, a memory layer for AI agents, and decided to benchmark it against Mem0 — the most-funded memory infrastructure company in the space ($24M raised). We picked LoCoMo, the standard academic benchmark, and ran 10 multi-session conversations through both systems.
What we found surprised us.
What Mem0 stored vs what was actually said
LoCoMo includes a 19-session conversation between Caroline and her friend Melanie. In session 4 — June 27, 2023 — Caroline tells Melanie:
"Lately, I've been looking into counseling and mental health as a career. I want to help people who have gone through the same things as me... Last Friday, I went to an LGBTQ+ counseling workshop and it was really enlightening. They talked about different therapeutic methods and how to best work with trans clients."
A real event. A real conversation. A real date.
Here's what each memory system extracted from this:
| System | Stored memory |
|---|---|
| Mem0 | "User attended an LGBTQ+ counseling workshop on Friday, April 23, 2026, which was enlightening; the session covered therapeutic methods for trans clients and featured passionate professionals." |
| Aurra | "Caroline attended an LGBTQ+ counseling workshop last Friday" |
The event is real. Both systems captured the workshop. Mem0 stored it 2 years and 10 months in the future — and threw in "featured passionate professionals," which was never in the source conversation.
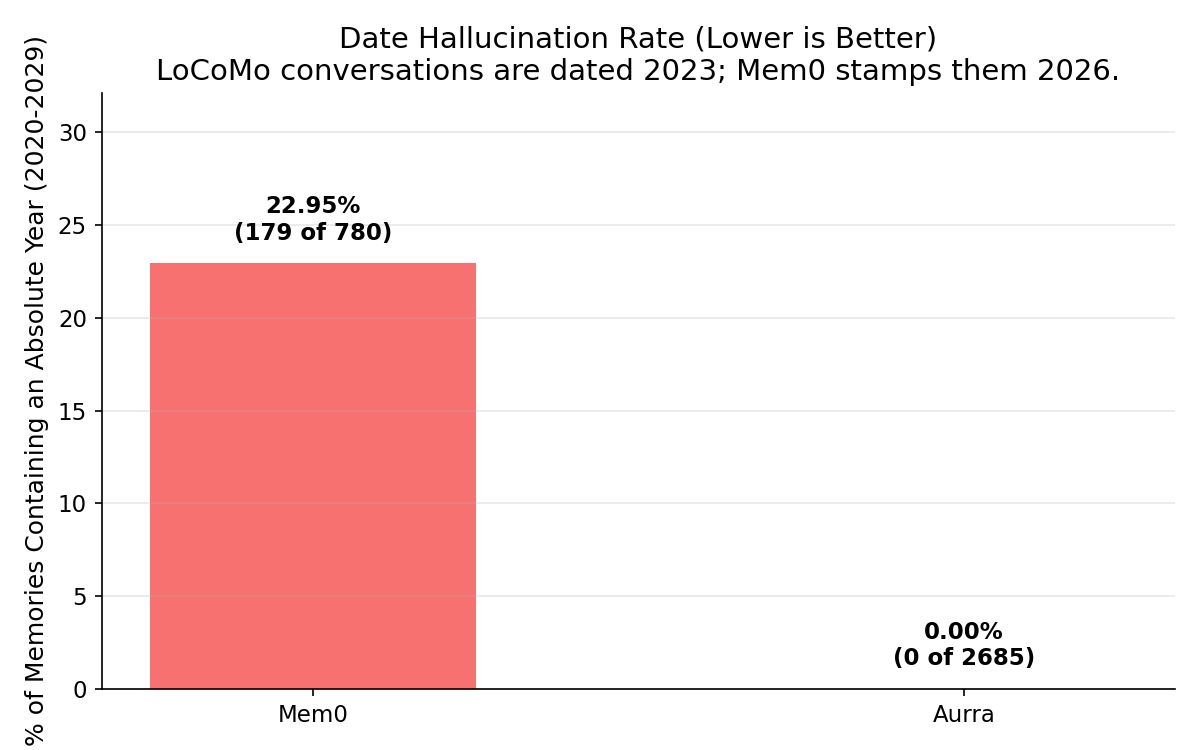
We checked the rest of Mem0's stored memories with absolute dates. The overwhelming majority used 2026 — today's date — even though every LoCoMo conversation is timestamped between June and October 2023.
Why this matters
Memory is the foundation of personalized AI agents — the thing that lets your AI assistant remember you across sessions. If the memory layer fabricates timestamps, every recalled event is mis-dated.
An agent built on Mem0 today, ingesting today's conversation, will store "user mentioned a panic attack" with the date 2026-04-29. Six months from now, when the user says "I haven't had one in a while," the agent retrieves that memory and confidently reports "your last panic attack was six months ago." The user actually had it eight months ago — the original event was already two months old when Mem0 stamped it. The agent is now lying to the user with full confidence, in a domain where the user might be making decisions based on the lie.
For an agent meant to maintain context over months, this isn't a small bug. It's a foundational one.
What we tested
LoCoMo (paper, data) is an academic benchmark of long-term conversational memory: 10 synthetic but realistic multi-session conversations, totaling 5,882 turns across 272 sessions. Each session has a real timestamp from June–October 2023.
We fed every session through both systems' standard add() methods. Same conversations, same speakers, same per-conversation isolation. Then we examined what each system actually stored.
All code, data, and results are open-source: github.com/aurra-memory/benchmarks. You can re-run it and get your own numbers.
Findings
Finding 1: Mem0 fabricates dates
Across the 10-conversation run:
| Metric | Mem0 | Aurra |
|---|---|---|
| Memories stored | 780 | 2,685 |
| Memories with absolute years | 179 (22.95%) | 0 (0.00%) |
Aurra never stores absolute dates currently — it preserves relative phrases as said ("last Friday", "recently", "three years ago"). Mem0 attempts to ground dates absolutely, and the overwhelming majority resolve to today's date.
A few more examples from the same conversation, all timestamped 2023 in the source:
- "Assistant noted she has been married for five years as of April 2026, meaning she married around 2021."
- "Assistant (Melanie) mentions her kids are excited about the upcoming summer break and that the family is planning a camping trip in May 2026."
- "Assistant purchased figurines on 2026-04-28, noting they remind them of family love."
Each of these is a real fact the source conversation contained. Each got a fabricated date attached.
Finding 2: A silent 100-memory cap
While processing the run, we noticed something odd: six of our ten conversations stored exactly 100 memories in Mem0. Not 99, not 103. Exactly 100, six times.
Mem0's free-tier API silently caps stored memories at 100 per user_id. Sessions beyond that aren't ingested. There's no error. We only caught it because the numbers were suspiciously round.
This is a different kind of bad than fabrication. Fabrication is loud-wrong; silent caps are quiet-wrong. Quiet-wrong is worse for production systems because you don't know it's happening — your agent just stops remembering things and you have no signal.
The paid tier may behave differently. Free tier is what shows up in pip install mem0ai and what most builders will try first.
Finding 3: Memory volume
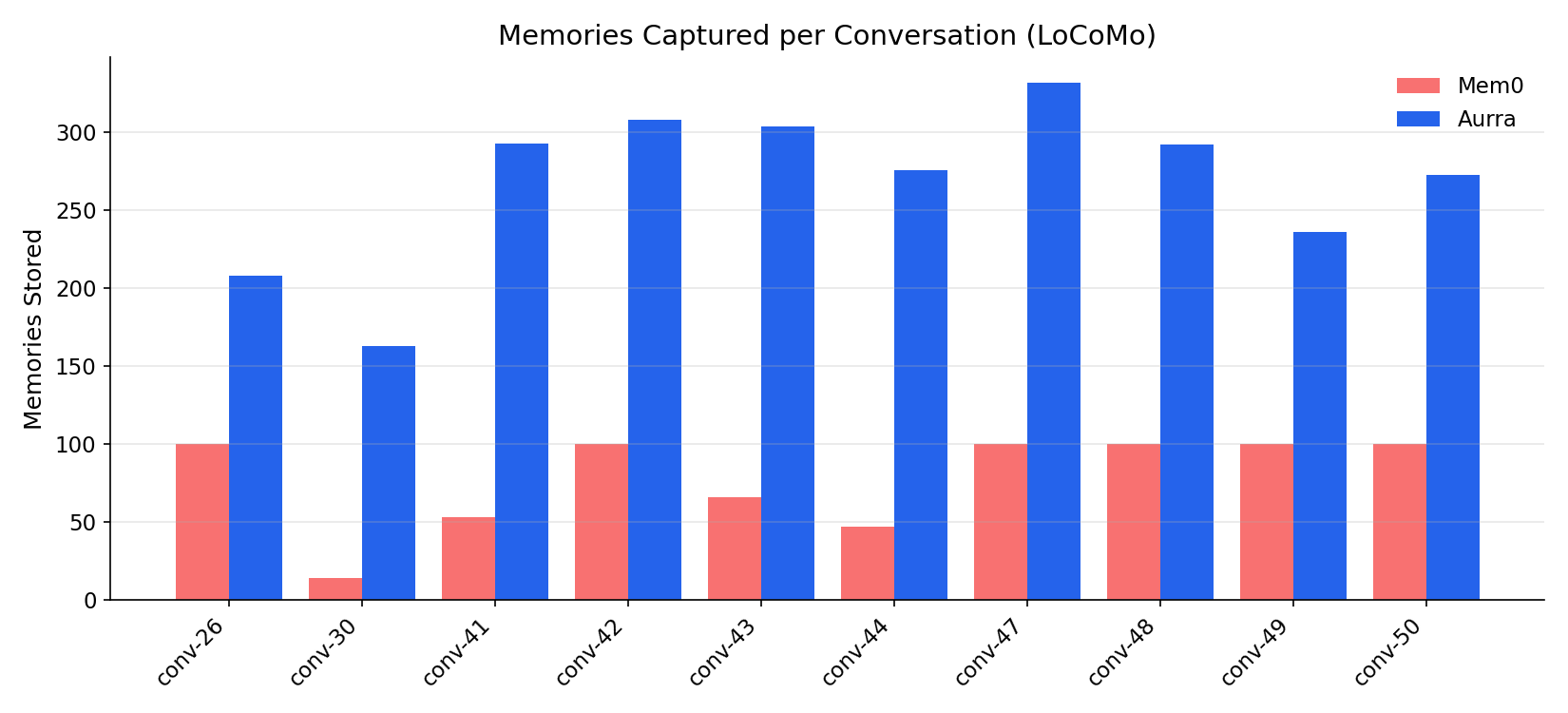
Aurra captured 2,685 total memories across 5,882 turns. Mem0 captured 780 (capped, as noted above). That's a 3.4× difference, though Mem0's cap makes the comparison imperfect.
We don't claim more memories = better. Selectivity matters. But Mem0's extraction is clearly more aggressive in summarizing — and that aggression is what introduces fabrication. Each summary requires the model to fill in details that weren't in the source. "Workshop last Friday" becomes "workshop on Friday, April 23, 2026" because something has to fill the date slot.
Finding 4: Quality scoring (with a heavy caveat)
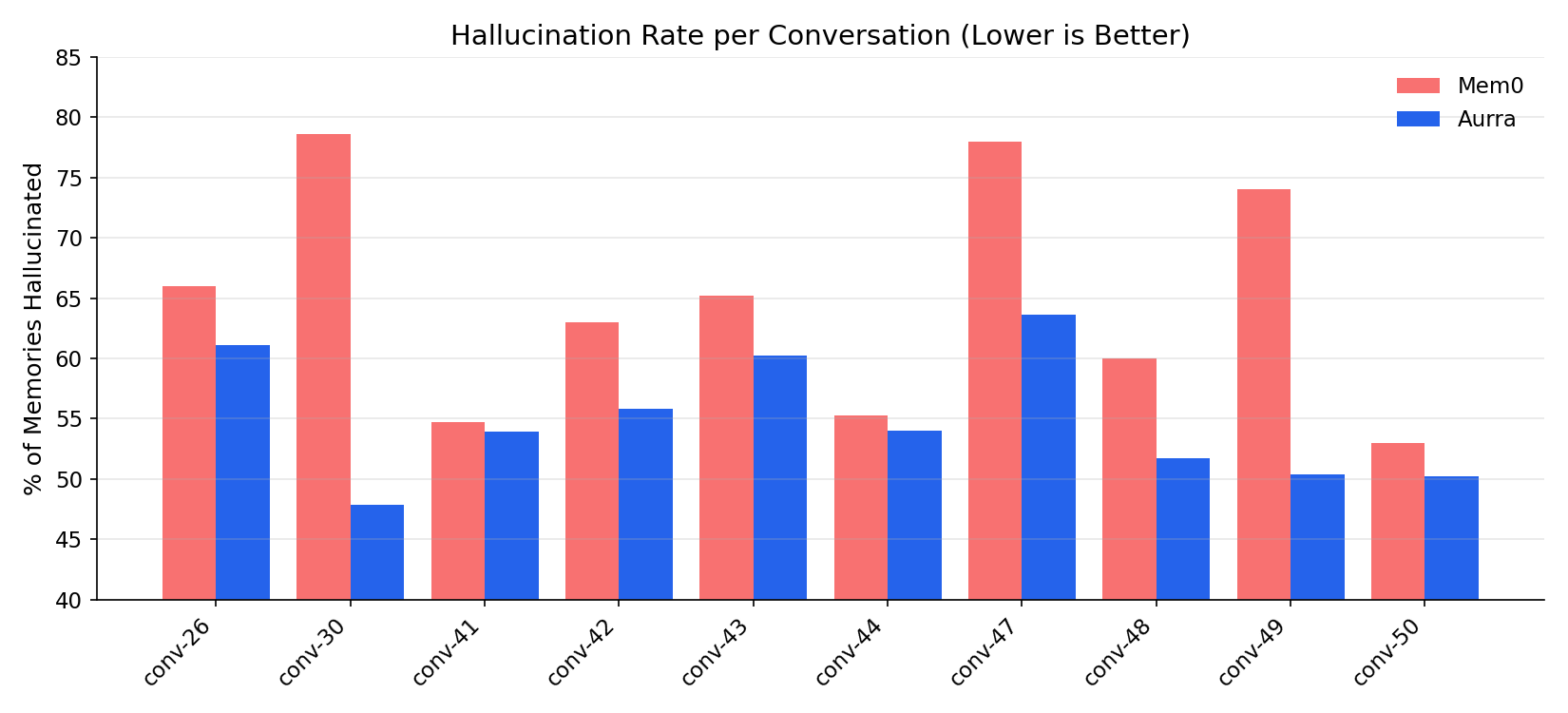
We also ran an LLM-as-judge (Claude Opus) over every memory both systems stored. The judge classified each memory as useful, hallucinated, junk, or misattributed against LoCoMo's event_summary ground truth.
Before reading the numbers, the caveat: LoCoMo's event_summary is brief and incomplete. Memories about real but unsummarized content get flagged as hallucinated. Absolute hallucination rates are inflated for both systems. The relative comparison is the meaningful signal.
| Classification | Aurra | Mem0 |
|---|---|---|
| Useful | 42.4% | 28.2% |
| Hallucinated | 55.3% | 64.5% |
| Junk | 2.6% | 5.9% |
| Misattributed | 1.7% | 7.2% |
Aurra is roughly 1.5× as useful per stored memory, with lower rates across all three failure modes. The pattern holds per-conversation, not just on average.
What Aurra does instead — and what's coming
Aurra currently doesn't store absolute dates inline. This is conservative: we don't fabricate what we don't know. We preserve relative time language as said.
But this isn't the final answer. Real memory needs structured time, queryable across sessions. We're shipping bi-temporal versioning in the next two weeks. Every memory gets two timestamps:
- said-on: the timestamp when the user said it (from session metadata)
- valid-from / valid-to: when the fact was actually true (or true-as-of)
When Caroline says in June 2023 "Last Friday I went to an LGBTQ+ counseling workshop", we'll store:
Fact: "Caroline attended an LGBTQ+ counseling workshop" said-on: 2023-06-27 valid-from: ~2023-06-23 (the prior Friday)
No fabrication. No temporal drift. Queryable across sessions.
Caveats
- This benchmark used Mem0's free tier. If their paid tier behaves differently, we'll re-run and update.
- Mem0 ingests asynchronously. We waited 120 seconds after each conversation for indexing.
- Aurra's extraction uses Claude Opus. Mem0's extraction stack is closed-source. Different LLM choice may explain part of the quality difference.
- LoCoMo conversations are synthetic. Real production conversations may behave differently.
- We benchmarked on the standard 10-conversation LoCoMo subset. A larger sample would strengthen claims.
- LLM-as-judge introduces grader variance, and the judge's ground truth is incomplete (see Finding 4 caveat).
Try Aurra
Aurra is currently in private beta. We're inviting AI builders who care about getting memory right.
pip install aurra
from aurra import Aurra
mem = Aurra(api_key="...")
mem.add(messages=[
{"role": "user", "content": "Hi, I'm Alice and I love pickleball"},
])
results = mem.query("What does Alice like?")
Email support@aurra.us for access.
Benchmark code, data, and results are open-source at github.com/aurra-memory/benchmarks. Clone it, re-run it, file issues. PRs welcome.